많은 사람들은 파이썬 dict와 set이 빠른 것을 안다. 또한 이들의 key 순서가 유지되지 않는 것도.
이러한 dict와 set의 특성을 내부구조를 파악하며 설명해보려고 한다.
성능 실험
다음과 같은 예제에서 haystack 안에 있는 needles를 검색하고 발견된 횟수를 찾는 프로그램을 비교 실험한다.
found = 0
for n in needles:
if n in haystack:
found += 1
실험결과는 fluentpython.com의 아래 테이블을 참조하였다.
haystack의 크기를 10배씩 늘려가며 각각의 자료구조에서 키를 검색하는데 걸리는 시간을 비교하였다.

예상했던 바와 같이 haystack의 크기가 10,000X로 천만단위가 되어도 dict와 set의 키 검색시간은 3.5~5.1X를 유지하며 높은 효율을 보여주었다. 그리고 list의 키 검색시간은 8,618X로 거의 haystack의 크기 수준을 따라가는 듯 보였다.
해시 테이블
이러한 성능 차이를 보인 dict와 set의 내부구조는 해시 테이블로 구현되어 있다. 해시 테이블은 sparse array이다. 이 해시 테이블 안에 있는 항목들을 버킷이라고 하는데 dict 해시 테이블에는 각 항목별로 버킷이 있고, 버킷에는 키에 대한 참조와 항목의 값에 대한 참조가 들어간다.
파이썬은 버킷의 1/3 이상을 비워두려고 노력한다. 해시 테이블 항목이 많아지면 더 넓은 공간에 복사해서 버킷 공간을 확보한다.
해시 테이블 알고리즘
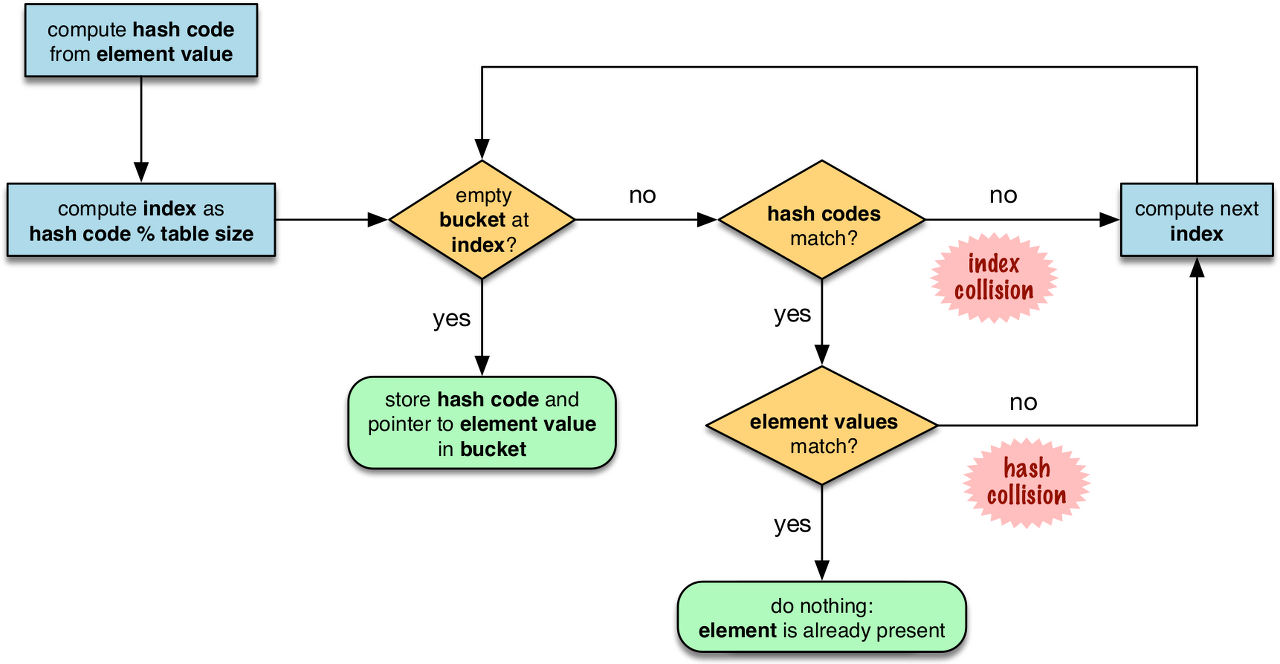
dict에서 검색하는 값을 가져오기 위해 파이썬은 __hash__를 호출해서 키의 해시값을 가져오고, 해시값의 최하위 비트를 해시 테이블 안의 버킷에 대한 오프셋으로 사용한다. 찾아낸 버킷이 비어있으면 KeyError를 발생시키고, 그렇지 않으면 버킷에 들어있는 (key, value) 쌍을 검색해서 검색한 키가 발견한 키와 일치하는 지 검사한다. 여기에서 이 값이 일치하면 value를 반환한다.
이 값이 일치하지 않는 경우 hash collision이 발생한 것이다. 이를 해결하기 위해 해시값의 다른 비트들을 가져와서 다른 버킷들을 조회하고 키가 일치하면 항목을 반환하고, 이때에도 버킷이 비어있으면 KeyError를 발생시킨다.
해시 테이블의 한계
이러한 dict의 해시 테이블은 매우 효율적으로 보이지만 해시 테이블의 특성 때문에 몇가지 한계점도 동시에 존재한다.
1. 키 객체는 항상 hashable 해야한다.
아래의 요구사항을 만족하는 객체는 hashable 하다고 볼 수 있다.
- 객체의 수명주기 동안 언제나 동일한 값을 반환하는 __hash__ 함수를 제공해서 해시를 지원하고,
- __eq__ 함수를 통해 동치성을 판단가능하며,
- a == b 가 참이면, hash(a) == hash(b) 도 반드시 참이어야 한다.
2. dict의 메모리 오버헤드가 크다.
dict의 메모리 공간 효율성은 높지 않다. 많은 양의 레코드를 처리하는 경우에는 Json 형태로 각 레코드에 하나의 dict를 할당해서 딕셔너리의 리스트를 사용하는 것보다 튜플이나 튜플의 리스트에 저장하는 것이 좋다.
dict가 내부적으로 해시 테이블을 사용하고 해시가 제대로 작동하려면 버킷의 빈 부분이 충분해야 하기 때문이다.
3. dict에 항목을 추가하면 기존 키의 순서가 변경될 수 있다.
파이썬은 dict에 항목을 추가할 때마다 그 딕셔너리의 해시 테이블 크기를 늘릴지 판단한다. 그리고 더 큰 해시 테이블을 새로 만들어서 기존 항목을 모두 새 테이블에 추가한다. 이 과정 동안 기존과 다르게 hash collision이 발생해서 새로운 해시 테이블에서의 키 순서가 달라질 수 있다.
마치며
dict와 set의 기반이 되는 해시 테이블은 매우 빠르고 큰 데이터에 대해서도 잘 동작한다.
그러나, 메모리 공간을 많이 사용하며 키의 순서를 유지하지 않으며 키값에 대한 제약도 존재한다.
원문: https://www.fluentpython.com/



