Elastic Stack은 대용량의 로그, 네트워크, 보안 데이터, 시계열 데이터 및 기타 데이터를 수집, 저장, 검색, 분석하고 시각화할 수 있는 4가지 기술을 의미한다.
- Elastic Search: 대용량의 데이터를 검색하고 분석
- Logstash: 데이터 수집, 가공, 적재
- Kibana: 데이터 시각화 웹 인터페이스
- Beats: 시스템, 네트워크, 보안 데이터 등을 수집
이 중에서, Elastic Search는 데이터를 저장/검색/분석하는 Elastic Stack의 심장부 역할을 한다.
Elastic Search는 언제 사용하는가?
Elastic Search는 데이터 검색에서 Speed & Relevancy를 해결해주는 도구이다.
1. 고객이 제품을 검색
- Elastic Search는 데이터베이스의 규모가 어떻든 간에 고객이 균일하게 빠르고 연관된 검색 결과를 받게 도와줌
2. 고객이 연관 제품을 탐색
- Elastic Search는 인덱싱을 통해 고객 경험에 있어서 연관 있는 제품 순으로 데이터를 탐색하는 것을 도와줌
Elastic Search 기본 구성요소
1. 노드(Node): Elastic Search의 기본 단위
Elastic Search를 실행시키고 생성되는 인스턴스 → 노드
- 각각의 노드는 유니크한 ID와 이름을 가짐
- 각각의 노드는 하나의 클러스터에 속하게 됨
2. 클러스터(Cluster): 노드들의 집합

노드 생성시, 클러스터가 자동으로 생성되어 해당 노드를 감싸게 된다. 하나의 클러스터에는 1개 이상의 노드를 포함할 수 있다. 이러한 노드들은 각기 다른 머신에 분산되는데, 위 노드들은 하나의 클러스터에 속하고, 동일한 태스크를 달성하기 위해서 결성된다.
예를 들어 설명하자면, 동일한 목적을 달성하기 위해 구성된 팀, 각각의 팀원은 해당 목적을 달성하기 위해 태스크를 쪼개어 각자 본인 특화 분야에서 일을 하는 것으로 생각할 수 있다.
- 각 팀원은 다른 건물에서 일할 수 있음(각 노드는 다른 머신에 분산)
- 각 팀원은 하나의 팀에 속하여 같은 목적을 달성하기 위해 일함(각 노드는 하나의 클러스터에 속하여 동일한 태스크를 수행)
3. 도큐먼트/인덱스(Document/Index): 데이터의 저장단위
{
name: "Clementines(3lb bags)"
category: "Fruits"
brand: "Cuties"
price: "$4.29"
}도큐먼트는 JSON 오브젝트이면서, Elastic Search에 저장하고 싶은 어떤 형태의 데이터이든 들어갈 수 있다.
- 비슷한 특성을 가진 도큐먼트들을 묶어서 관리할 수 있다
- 비슷한 특성을 가진 문서들을 묶어주는 것이 인덱스
4. 샤드(Shard): 실제 데이터가 저장된 곳이며, 실제 검색을 수행하는 곳
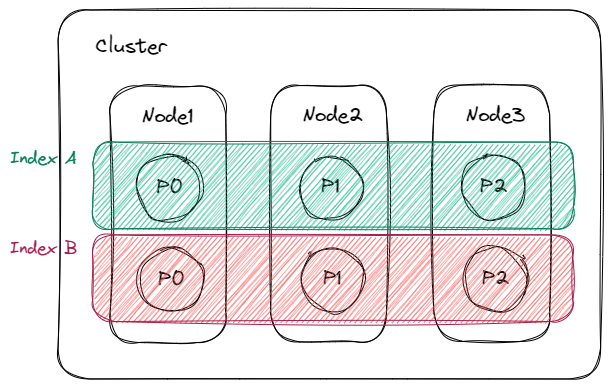
실제로 인덱스를 하나 생성하게 되면 기본적으로 샤드 하나가 생성되어 배치되며 이 샤드 들은 각 인덱스에 속하는 노드에 하나씩 생성된다. 이렇게 노드별로 인덱스의 샤드들을 나누어 분산 배치하는 것을 샤딩(Sharding)이라고 하며 이 개념으로 Elastic Search에 엄청난 힘이 부여된다.
샤딩 시나리오 #1: Data distribution

- 600K 규모의 도큐먼트들을 인덱싱하고 싶은데 하나의 노드 서버에 200K 데이터만 저장할 수 있는 상황
- 같은 클러스터의 노드일 경우 샤딩은 각 인덱스의 데이터를 200K씩 나누어 저장해서 인덱싱하는 것을 가능하게 해준다
샤딩 시나리오 #2: Data scale-out

샤드는 실제 도큐먼트를 저장하며, 검색 쿼리를 수행하는 곳이다. 샤딩은 Elastic Search에 데이터를 많이 저장할 수 있게 도와줄 뿐 아니라, 검색도 병렬로 할 수 있게 해준다.
샤딩을 통해 데이터의 규모를 늘리고, 분산 저장/검색하여 퍼포먼스 향상시키기
- 초기에는 하나의 노드에 전체 인덱스를 포함하는 샤드를 저장
- 이 노드가 500K의 문서를 저장하고, 해당 쿼리의 검색이 500K에 대해 순차적 일어날 시 → 10초가 걸린다는 상황
- 그러면 이 인덱스를 10개의 노드에 걸쳐서 shard를 분할하고 이것에 대해 검색을 수행한다면? → 50K의 문서로 분할, 1초에 모든 노드들이 검색을 병렬 수행할 수 있다!
샤딩 시나리오 #3: Fault taulerance

클러스터의 특정 노드가 죽는 상황을 대비하여 샤드들의 복사본을 저장, 각각의 노드들에 백업해 놓을 수 있다.
- 노드1/2 → 원본 데이터 샤드, Primary Shard를 저장하는 노드
- 노드3/4 → 백업 데이터 샤드, Replica Shard를 저장하는 노드
이렇게 구성시, 노드 1/2가 죽어도 백업 샤드에서 데이터 복구가 가능
- Replica Shard는 데이터 백업뿐만 아니라 검색 퍼포먼스에도 도움을 준다 → R0/1은 P0/1과 완전히 동일한 Shard이기 때문에 각 클러스터에서 이 두 노드에서 분할하여 검색을 수행할 수 있다!



